파이썬을 이용한 업무 자동화 방법 아래에서 원하는 메시지를 스크래칭하는 방법을 배웠습니다. 단계를 순서대로 따르면 원하는 메시지를 원하는대로 긁을 수 있습니다. 프로그래밍을 처음 배워서 배운 내용을 정리하고 기록하기 위해 이 글을 씁니다.

뉴스 검색 페이지로 이동
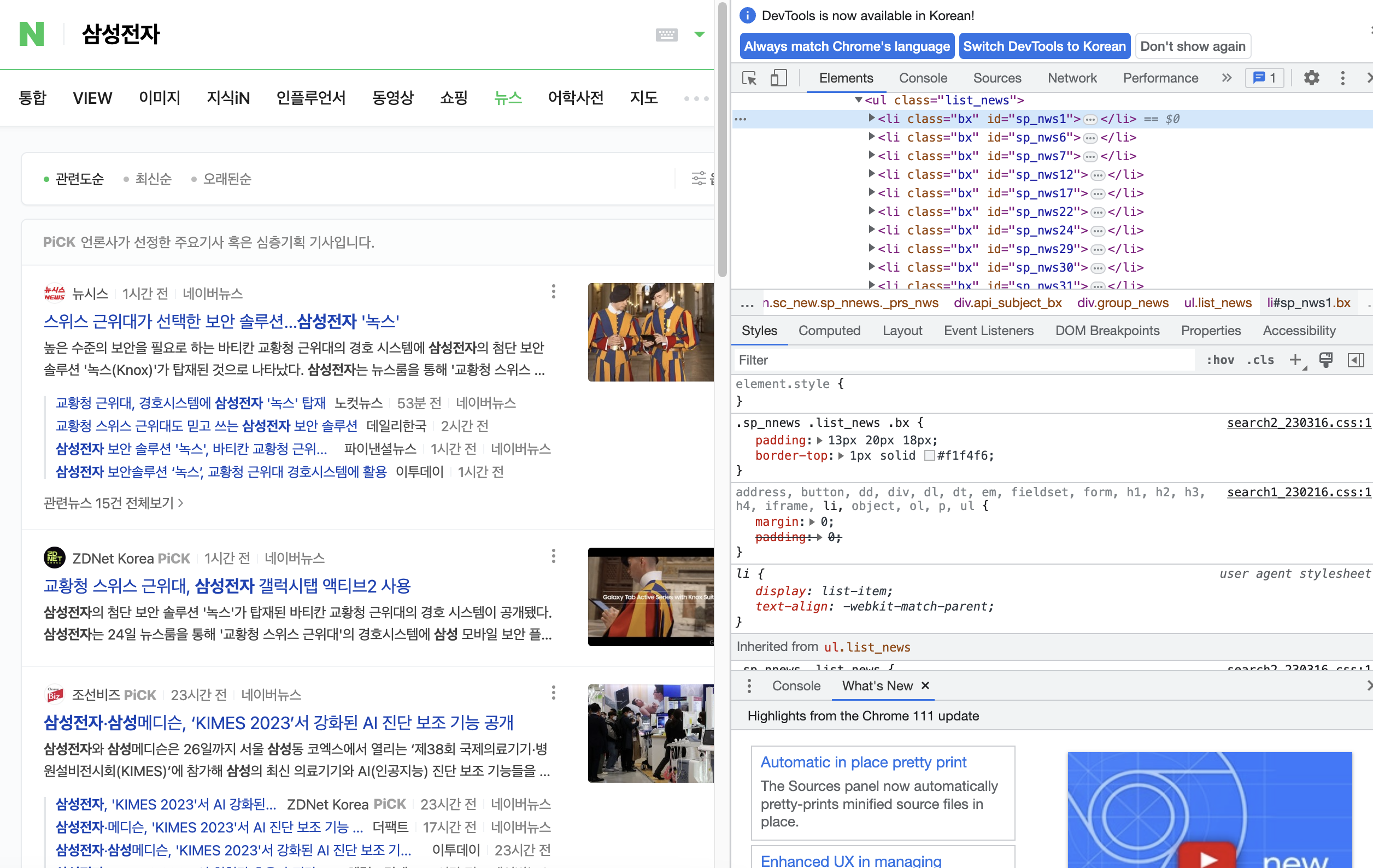
원하는 메시지가 있는 검색 페이지로 이동합니다. 검색창에 원하는 검색어를 입력 후 검색 후 (우클릭) – (조사)를 클릭하면 아래와 같은 화면이 나타납니다.

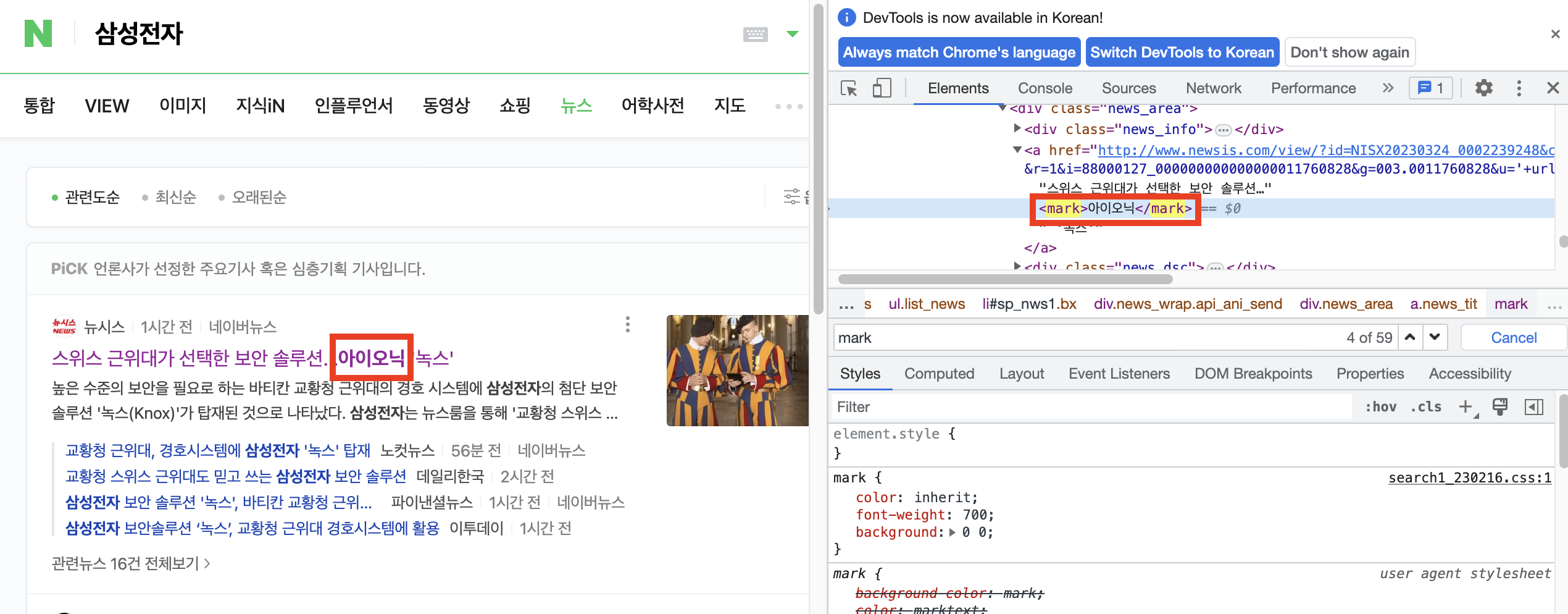
오른쪽 화면에서 마크를 찾으면 검색창에 검색한 단어가 포함됩니다. 다른 단어로 변경하면 왼쪽 검색창에 기존 검색어가 표시되고 변경한 단어로 대체됩니다. 단어를 변경한다고 해서 변경한 단어가 다른 사람에게 표시되는 것은 아닙니다. 하지만 수신된 데이터만 처리했기 때문에 다르게 보일 뿐입니다.
즉, 이미 가지고 있는 정보를 솎아냄으로써 원하는 정보만 긁어내는 것이 가능하다. 크롤링의 기본 코드는 다음과 같습니다. 복사하여 붙여넣은 후 메시지 스크랩을 시작하겠습니다.
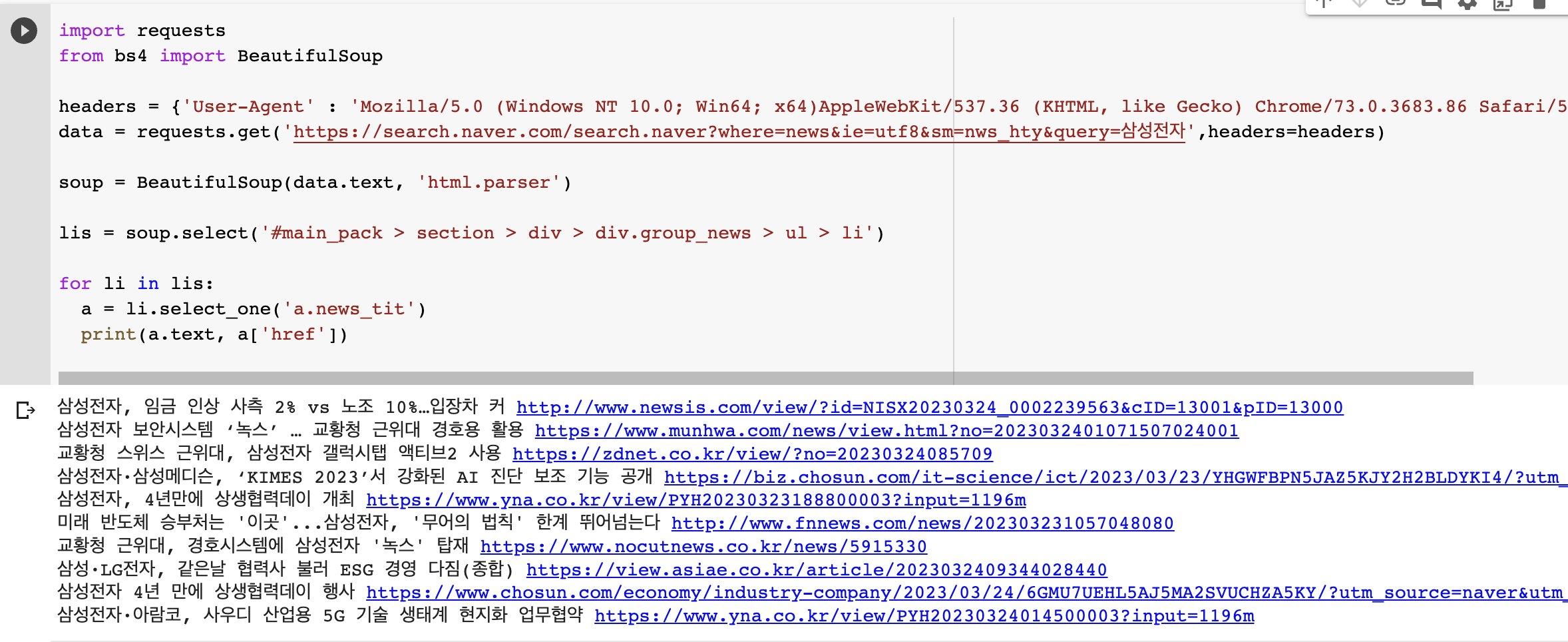
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://search.naver.com/search.naver?where=news&ie=utf8&sm=nws_hty&query=삼성전자',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
네이버 뉴스 스크래핑 시작


먼저 bs4를 설치합니다. Ctrl+Enter 또는 왼쪽 재생 버튼을 눌러 실행합니다. 완료되면 이전에 열었던 검색 창으로 돌아갑니다. 당신 후 마우스 오른쪽 버튼을 클릭하고 (복사) – (선택 복사)를 선택합니다.
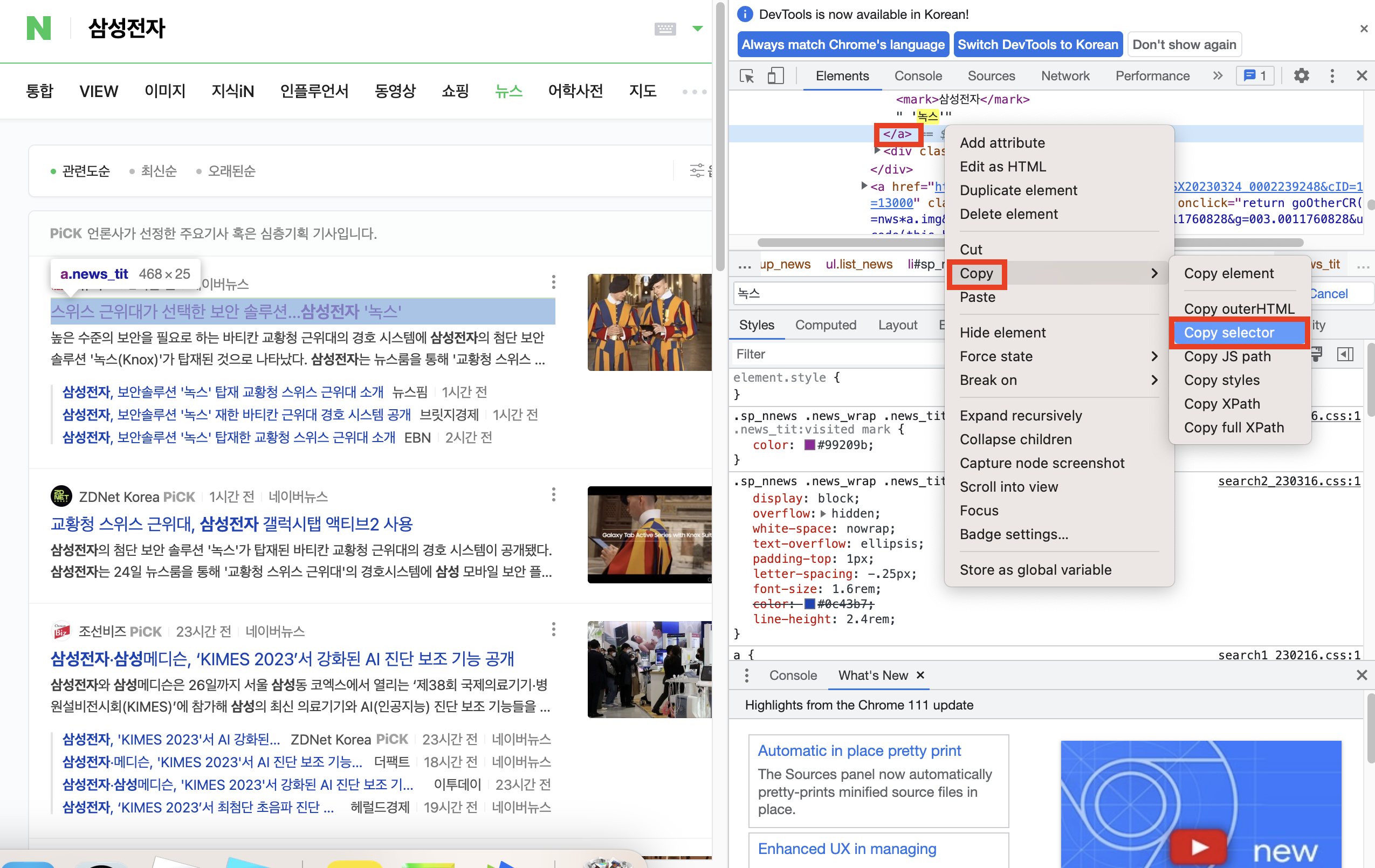
코드 입력 창으로 돌아가서 다음을 입력하십시오.
- 전체 내용을 보고 싶다면 압력(a)
- 에 포함된 텍스트만 보려면 텍스트

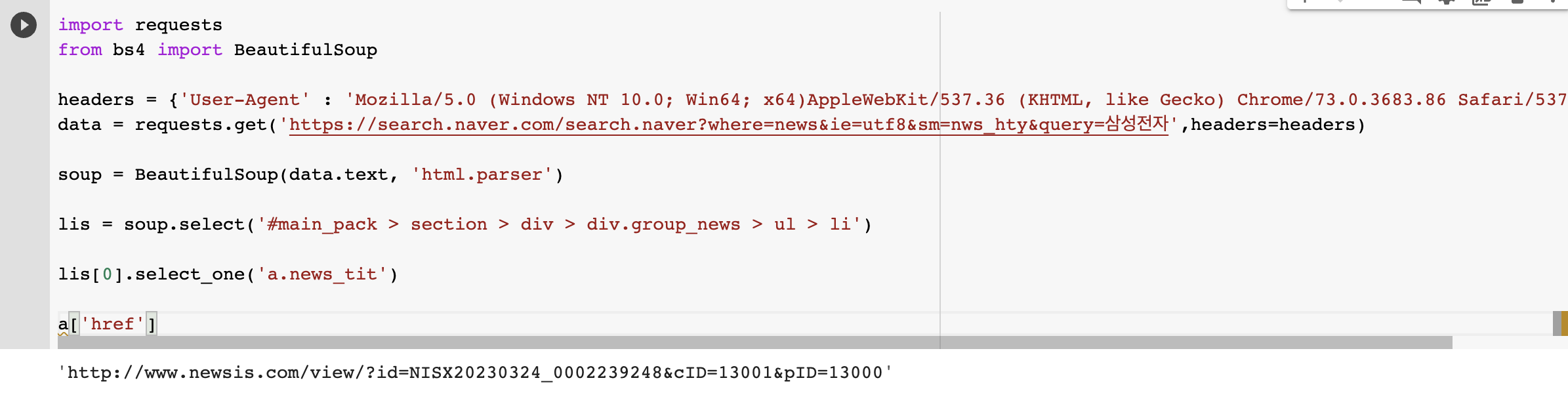
- 링크를 보고 싶다면 a(‘href’)
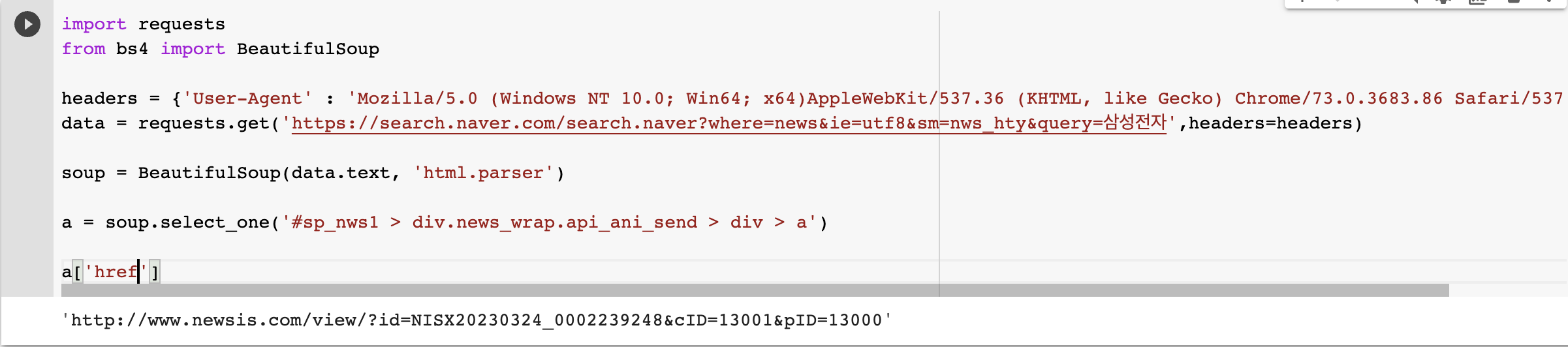
위의 세 가지를 결합하여 여러 메시지를 가져올 수도 있습니다.
- 메시지 목록의 첫 번째 메시지를 보려면
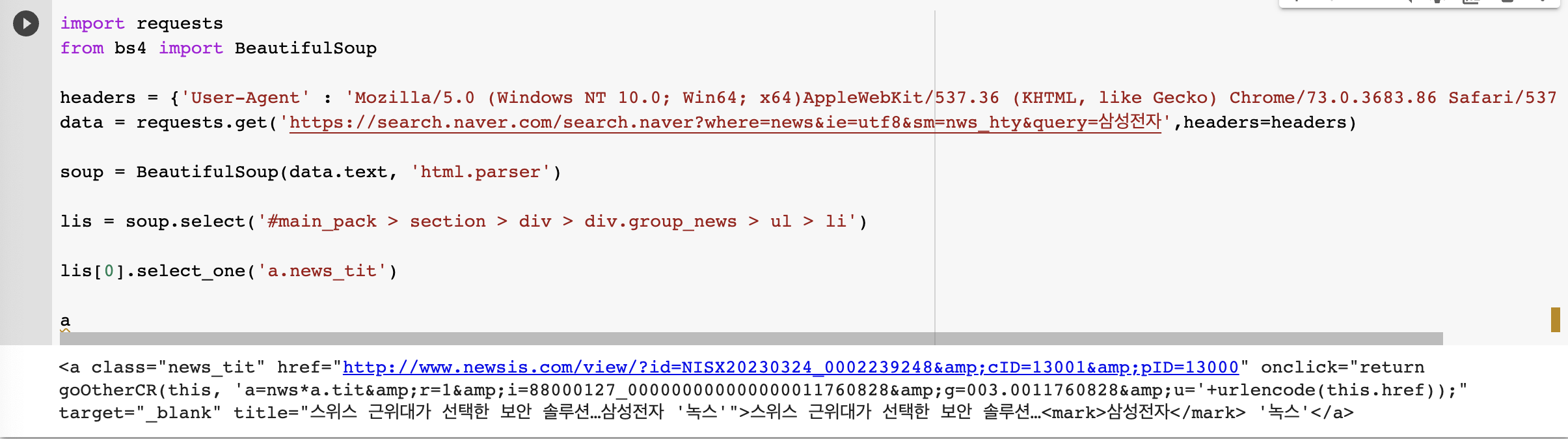
- 첫 번째 메시지(‘href’)의 링크를 보고 싶다면
- 리 인 리:
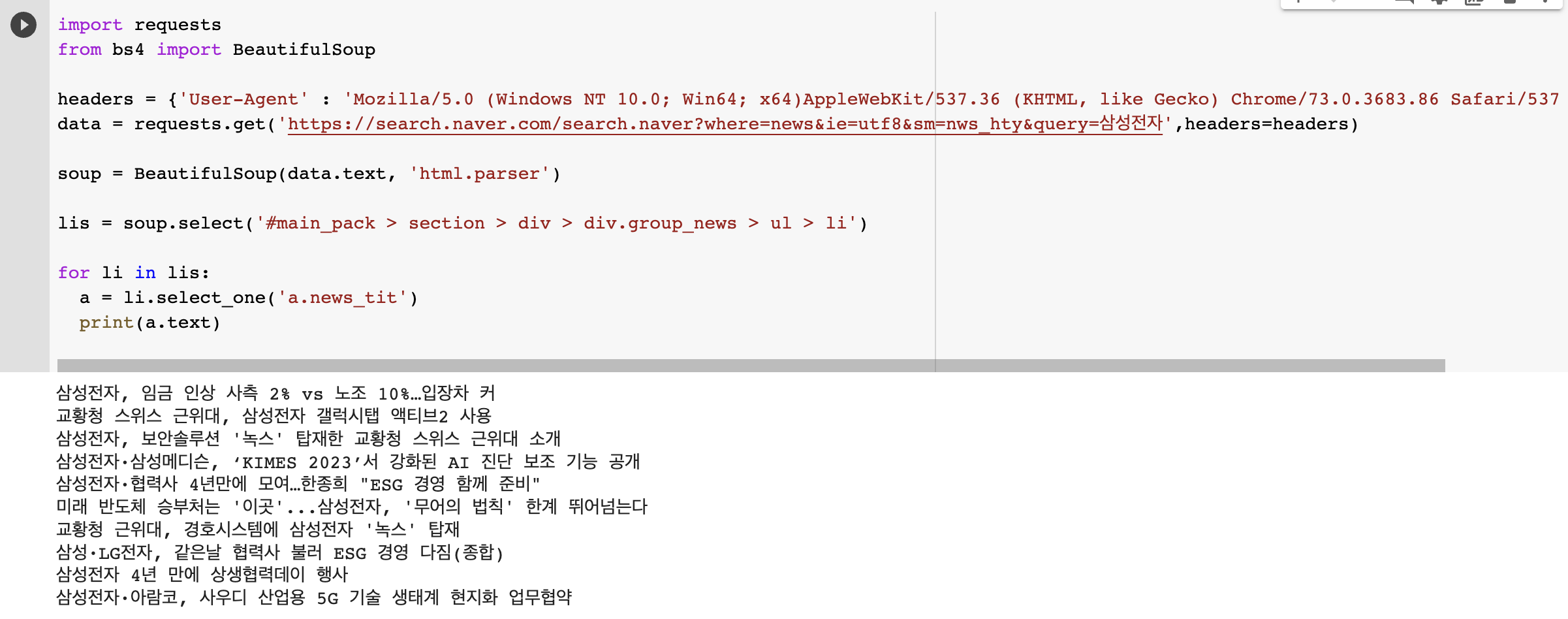
- 텍스트와 URL을 동시에 보려면 다음을 사용하십시오.
파이썬 기초를 배우고 있습니다. 오늘은 Python을 이용하여 검색창에서 원하는 뉴스를 스크랩하는 방법에 대해 알아보았습니다. 재미있지만 조금 어렵기도 합니다. 앞으로도 열심히 하겠습니다 😀